What can we learn from open science as we bring AI tools into academic research? BITSS Program Manager Jo Weech shares concerns and opportunities discussed at two research transparency conferences this spring: the BITSS Annual Meeting in Berkeley, CA and the MeasureDev conference in Washington, DC.

Left to right: Edward Miguel, BITSS Faculty Director; Arianna Legovini, Director of Development Impact Group, World Bank; Markus Goldstein, Vice President and Senior Fellow, Center for Global Development; Haishan Fu, Chief Statistician and Director of the Development Data Group, World Bank.
Artificial intelligence (AI) is already reshaping how we do research. We’ve all seen headlines about the possibilities AI could unlock in science and wondered about the ways it could lead us astray. What can we learn from open science as we discuss AI’s role in how research is conducted?
This spring, BITSS helped advance conversations about what AI means for research transparency at our Annual Meeting in Berkeley and MeasureDev conference in Washington, DC. Our main takeaway is that verifying research validity, data and code transparency, and data quality is especially vital as we incorporate AI into research. Large Language Models (LLMs) can synthesize evidence with unprecedented speed and efficiency, but without verifying study reproducibility and the quality of underlying data and evidence, we risk compounding biases and generating misleading insights for those basing high-stakes decisions on social science research. As such, the mission of the open science movement—to improve reproducibility, data and code transparency—is more important now than ever.
AI and Reproducibility
Reproducibility means re-analyzing a study’s original data and code to verify the findings. Two decades ago, concerns about the validity of academic research led to discussions of a “reproducibility crisis.” So how reproducible is academic research now? In April 2026, the Systematizing Confidence in Open Research and Evidence (SCORE) program–a collaborative effort involving 865 researchers–published a collection of three papers with new empirical evidence of reproducibility across the social sciences.
Out of a sample of 600 papers, the SCORE project was able to reproduce 143, finding that 74% of them reproduced at least approximately and 54% precisely (Miske et al., 2026). Since data availability is a minimum requirement for reproduction, the team was unable to complete reproductions for papers where data and code were available and where data, but not code, were available. Unsurprisingly, reproducibility rates were highest when both original data and code were shared. The below figure from the Miske paper shows that while data and code availability have increased in recent years, we still have a long way to go. Restricted data access remains a significant barrier to verifying reproducibility.
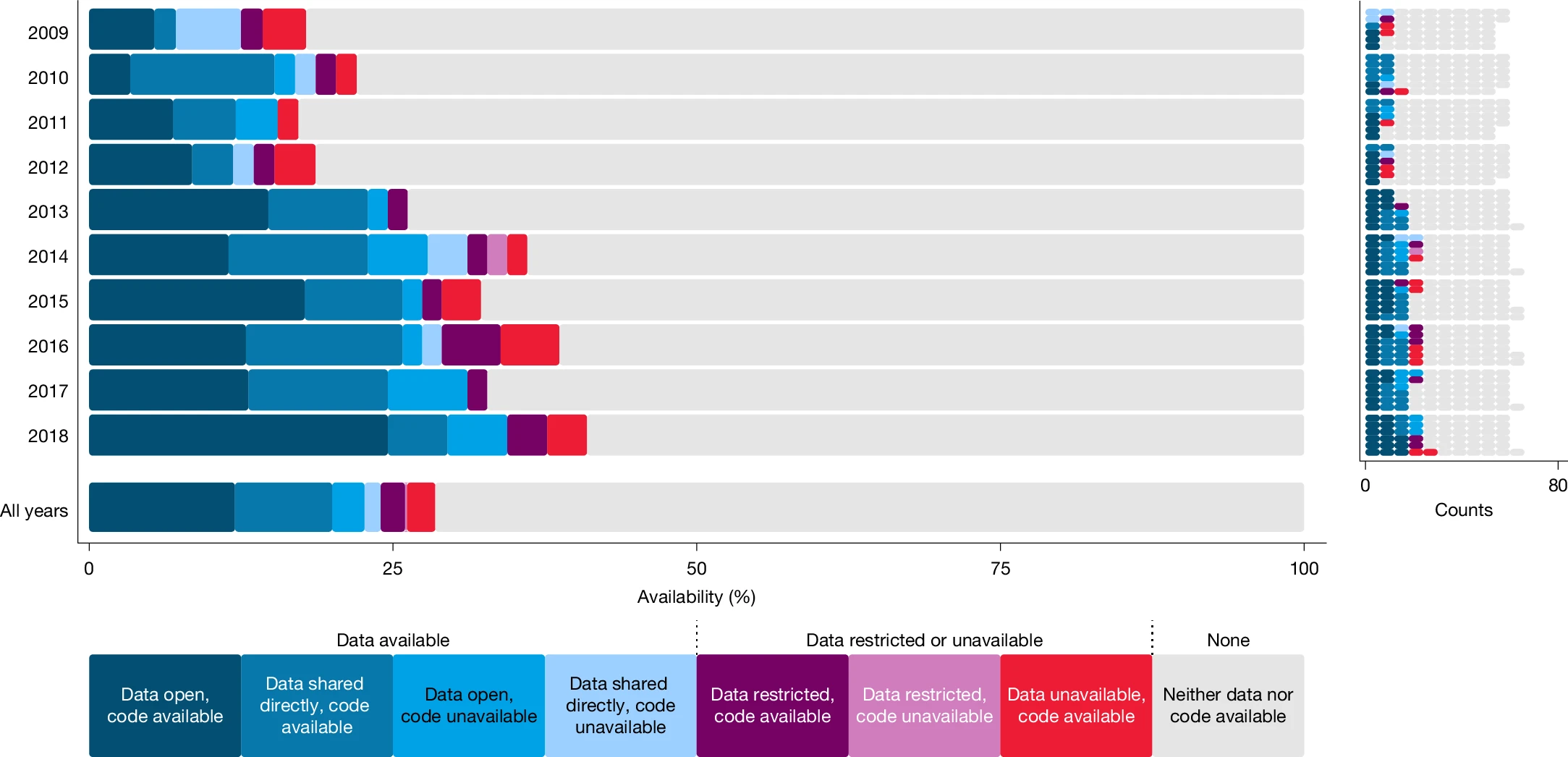
Synthesizing large bodies of academic research without first verifying that individual studies are reproducible—or at the very least that they have met minimum standards like making data and code available—is very risky. If we are using LLMs to synthesize findings from large collections of papers and at least a quarter of the papers being synthesized aren’t reproducible, this casts serious doubt as to the output of the LLM.
Additionally, research in which LLMs were used to conduct analysis can be irreproducible. When using commercially available models in a research workflow, there is always the possibility they could be deprecated and another scientist won’t be able to replicate the work. The underlying mechanics of many proprietary models are also hidden (except open source models), making it more difficult for researchers to see the inputs that led to the LLM outputs.
LLMs, especially reasoning models, output different answers to the same prompt. Using deterministic methods and other tools can help to make research reproducible even when using AI; but we don’t yet have clear best practices on how to conduct reproducible research with AI. Incorporating a “human in the loop” can feel counterintuitive when the goal of a project is automation, but without a reproducible way to use a reasoning model, it can be necessary to have a human verify the outputs (or at least a subset) of models.
Developing “push-button reproducibility checks” with AI would be a large boon. We are eager to see a tool developed that can ingest a paper’s code and data and automatically verify computational reproducibility. This could help catch basic errors that may lead to irreproducible research. Such a tool could also improve researcher’s robustness checks and provide other structured guidance to improve reproducibility. They could further be used to check the reproducibility of old studies where data and code are available, aggregating findings only from studies that are confirmed to be reproducible. Multiple organizations are working on this now, including the Institute for Replication (I4R) – you can read about their work here.
AI and Data Quality
When AI models are trained, the quality of the underlying data can limit their outputs. While reproducibility and transparency are two major concerns, there is also a third: the incompleteness of research data. Over the last three years, BITSS collected data on the completeness of results reporting in economic research through the Reporting Guidelines and Publication Bias (RGPB) project. This project looked at how many pre-registered hypotheses lead to publicly available results.

Photo: Sabrina Spatny, CEGA
Our team found across over 5,000 pre-registered hypotheses on the American Economic Association (AEA) Randomized Controlled Trial Registry, only 42% of hypotheses could be traced to publicly available results 8 to 9 years after pre-registration (Hoces de la Guardia et al., 2026). In other words, most results from pre-registered studies aren’t making it into published papers, and thus the training sets of AI models. This phenomenon has been previously discussed in the open science community in terms of how it biases results in published research through the suppression of null results. This remains a problem in the world of AI-enabled research, in that it potentially biases and limits the quality of AI-enabled tools built upon data from academic papers.
As part of the RGPB project, our team identified barriers preventing researchers from making all of their findings publicly available, and ran a randomized controlled trial (RCT) to determine that a simple intervention involving a standardized reporting template helped researchers make more of their results publicly available. Promoting the adoption of this tool at scale could both increase the reporting of research results and standardize reporting, making it easier for LLMs to ingest research results and conduct metaresearch.
AI and Open Science
AI can be an immensely powerful tool for researchers. It can provide tasks traditionally performed by research assistants, running analyses and cleaning data, and writing code. These tasks alone can speed up the research process. Attendees at conferences discussed using LLMs to develop websites and content to share their findings, as tools for checking their code, and many other applications.
However, if we use LLMs to pull findings from research without first addressing data reproducibility, quality, and transparency, then AI-enabled research won’t just face the same issues as existing research—it could amplify them. Adopting reforms championed by the open science movement is more important than ever. We must ensure that the research being produced with LLMs and other AI tools is verifiable and trustworthy, if we wish to generate findings that advance scientific research rather than degrade research quality.